
AIがどのようにデータを学び、ビジネスにどのようなインパクトを与えるのか、イメージできますか?AI技術の中心にあるのが「機械学習」と「ディープラーニング」という2つの学習技術です。
第2回目となる今回のブログでは、AIが学習を行う仕組みと、機械学習とディープラーニングの違いを詳しく解説していきます。データの重要性や、AIモデルの評価方法も併せて紹介し、AI導入の第一歩を確実に踏み出すための知識をお届けします。ビジネスにAIを活用するために、基本からしっかり理解していきましょう!
第1回目はこちらから👇

Contents
機械学習の仕組みとは?基本的な学習プロセスを解説
機械学習(Machine Learning)は、データからパターンを見つけ、それに基づいて新しいデータの予測や分類を行う技術です。これには、モデルを訓練する「学習プロセス」が必要です。学習プロセスは主に次のステップで進行します
- データ収集:最初に、モデルが学習するためのデータを集めます。このデータは、過去の売上データ、顧客の行動履歴など、ビジネスに関連する情報です。
- データの前処理:収集したデータはそのままでは不完全なことが多いため、クレンジングや整形を行います。例えば、不足している値を補完したり、外れ値を除去したりします。
- アルゴリズム選定:次に、使用するアルゴリズムを選びます。アルゴリズムには多くの種類があり、線形回帰や決定木、サポートベクターマシンなど、タスクやデータに応じて選択されます。
- モデルの訓練:前処理したデータを使ってモデルを訓練します。このステップでは、アルゴリズムがデータのパターンを見つけ、次に来るデータを予測する方法を学びます。
- モデルの評価:訓練されたモデルがどの程度正確に予測できるかを評価します。ここでは、新しいデータに対して予測を行い、結果を検証します。
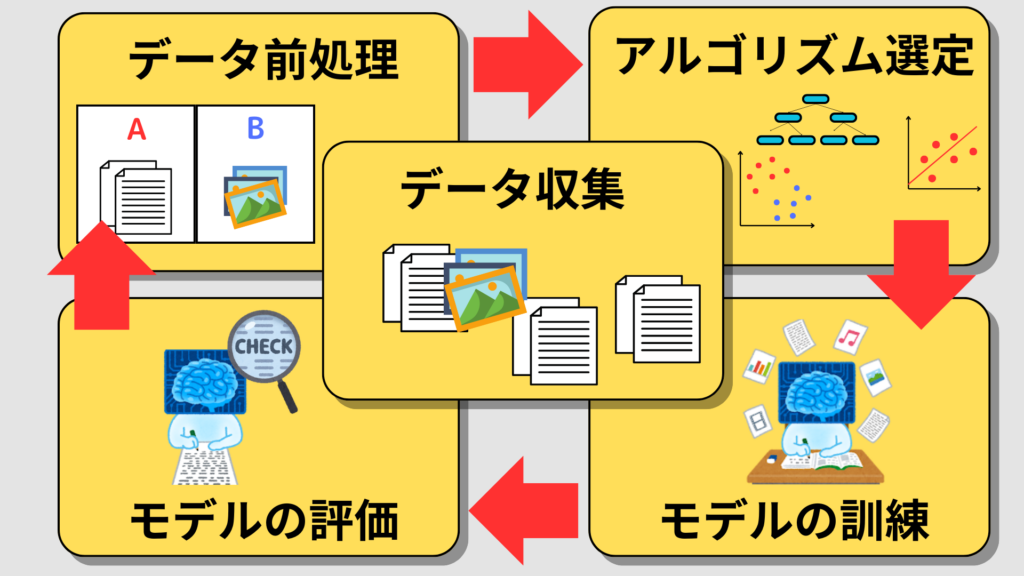
これらのプロセスを経て、モデルはデータに基づいたインサイトや予測を提供するようになります。ビジネスにおいては、売上予測や顧客行動の分析など、さまざまな場面でこの技術が活用されています。
機械学習とディープラーニングの違い
機械学習とディープラーニングは混同されがちですが、重要な違いがあります。機械学習は、特徴量と呼ばれるデータの重要な属性を人間が事前に選定し、それに基づいてモデルが学習を行います。一方、ディープラーニングは、これらの特徴量を自動的に抽出することができる技術で、より高度で複雑なデータを処理する際に使われます。
たとえば、画像認識のタスクでは、機械学習では画像内の色や形状などを特徴量として手動で選びますが、ディープラーニングではそれらを自動的に見つけ出し、画像が何であるかを判断します。これは、ディープラーニングが多数の層を持つ「ニューラルネットワーク」を使用しているためです。
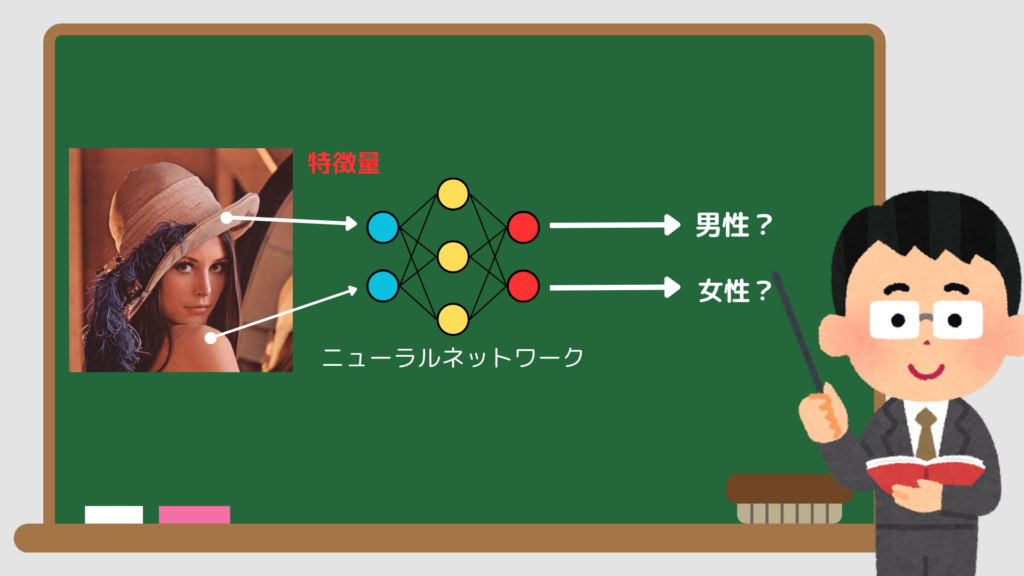
ビジネスにおいて、機械学習は比較的シンプルなタスク(例えば、顧客セグメンテーション)に適しており、ディープラーニングは高度な解析(例えば、画像分析や音声認識)に使われます。このように、目的やデータの複雑さに応じて、両者を使い分けることが重要です。
データの重要性とその前処理
AIや機械学習の成功は、良質なデータによって決まります。いくら高度なアルゴリズムを使用しても、データが不完全であれば、モデルの精度は低下します。そのため、データの前処理が非常に重要です。
データの前処理には、以下のステップが含まれます:
- 欠損データの補完:データセットに欠けている情報がある場合、それを補完する方法を選択します。統計的手法を使って推定したり、平均値や中央値を用いたりすることが一般的です。
- データの正規化や標準化:データのスケールが異なると、モデルが学習しにくくなることがあります。そのため、データの範囲を揃える作業を行います。たとえば、すべての値を0から1の範囲に収める「正規化」を行います。
- 外れ値の除去:データの中には、異常値や極端な値(外れ値)が存在することがあります。これらはモデルの精度を損なうため、適切に除去するか、修正します。
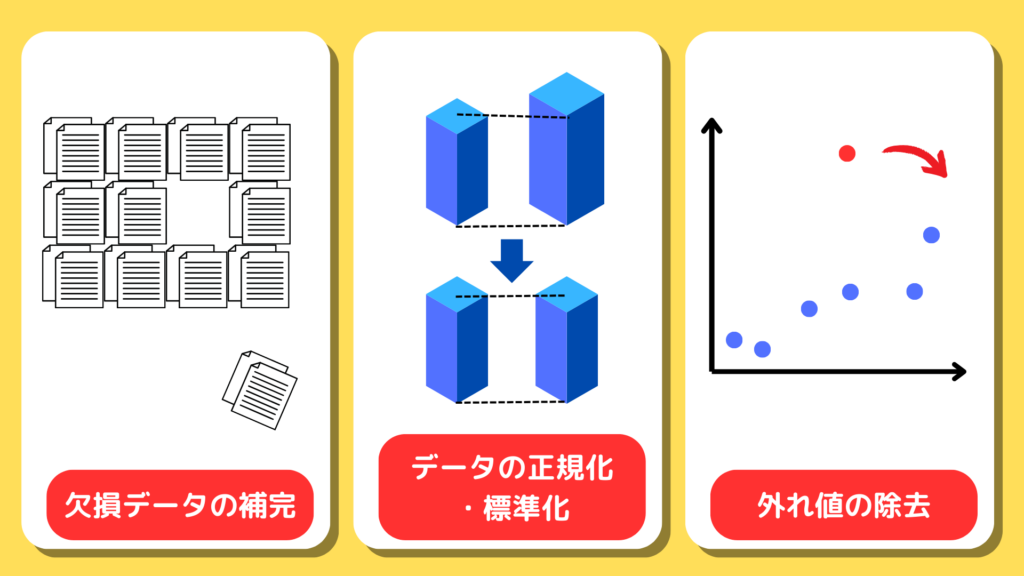
前処理されたデータは、AIモデルのパフォーマンスを劇的に向上させる可能性があり、特にビジネスでのAI活用においては、データの質が競争力の決定要因となります。
モデルの評価方法:正確な予測のために
AIモデルがどれだけ正確に予測を行えるかは、ビジネスにとって極めて重要です。モデルが間違った予測を行うと、ビジネスの意思決定に悪影響を及ぼします。そこで、モデルの性能を評価する方法について説明します。
主な評価方法としては以下があります:
- 正確性(Accuracy):予測がどの程度正しいかを示す指標です。全体の予測結果のうち、どれだけ正解したかの割合を表します。ただし、クラスの不均衡(例えば、不良品が1%しかない製品の品質検査)などがある場合、正確性だけでは不十分なこともあります。
- 精度と再現率(Precision & Recall):特に不均衡なデータセットでは、精度と再現率を重視します。精度は、予測が正しいとされたデータのうち、どれだけが実際に正しかったかを示し、再現率は実際に正しかったデータのうち、どれだけを正しく予測できたかを示します。
- F1スコア:精度と再現率のバランスを取った指標です。両者を一つの値にまとめ、モデルの全体的な性能を評価するのに役立ちます。
これらの評価指標を使うことで、モデルが現実のビジネスでどれほど有用かを見極めることができます。評価が適切に行われていれば、精度の高いAIをビジネスに導入し、予測や意思決定に役立てることができます。
まとめ:AIモデルの最適化でビジネスを強化する
AIや機械学習のモデルは、適切なデータと評価を経て最適化することで、ビジネスに大きな価値を提供します。データの前処理から、モデルのトレーニング、そして精度評価までの全てのプロセスが、最終的なビジネスの成果に直結します。
AIの導入には時間とコストがかかりますが、適切な手順を踏むことで、業務効率の改善や、顧客体験の向上、売上の最大化が期待できます。次回は、AIモデルの具体的な応用事例について詳しく解説していきますので、お楽しみに!
投稿者プロフィール






コメント